10 ideas to reverse engineer web apps : Web scraping 101
Nov 09, 2020TL;DR
1. Use ‘Elements’ tab of Chrome Dev tools to find out which element in the webpage has your data.
2. Avoid getting banned while developing by writing responses of target site in a file and using it for development.
3. Use ‘Network’ tab of Chrome Dev tools to find out structures of API calls and mimic an actual browser.
4. Parse HTML in dynamic sites only if there is no other way to do it. Try to figure out the API first.
5. Use regex to extract small pieces of information, don’t parse HTML for it.
6. Don’t overwhelm the API.
7. If you have to send a ton of requests, use proxies and shuffle user agents. (A nifty trick to use proxies mentioned on below)
8. If data is behind login pages, put wrong password once, capture the structure of the login request and use request.Session objects to login.
9. Use threadpool executor with proxies to send requests in parallel
10. Try interfacing with the mobile version of the same site if desktop version is too complicated.
11. Avoid using Selenium. Try to find out how the frontend of the APP is talking to the backend. Perform and action on the UI and capture the series of request that facilities the action using the Network tab.
(Example of a Reddit bot included)
Preface
Before we jump into the core of ideas of this post let’s talk about scope of web scrapping.
Why do web scraping?
May be you have a cool idea for an app or maybe you want to build an analytics solution for a problem that you have or you want to try out a machine learning algorithm on real world data. All these problem requires you to have some data to work with. And the internet has all of the data, quite literally. To be able to use data from the internet you need ways to interface with the internet programmatically. What where web scraping comes in. It is a way to get useful information from the internet.
Dynamic vs Static sites
There are sites which renders the contents of their pages on the backend and send an html page back. And there are sites which will send you an empty html template which it will fill up using the responses from some asynchronous API calls. Since lot of the sites now a days are highly dynamic, you will most likely face one of such site in your data gathering pursuit. This post will focus primarily on dynamically loaded websites.
So without wasting any more of your precious attention, let’s jump into why you are here.
Tools: Chrome Developer tools / Python / Requests / Selenium
- Chrome Developer tools: This is your best friend. This will greatly aid your development process. You will be able to explore structure of html pages, cookies, all the network calls to the severs and many more using this tool.
- Python / Requests: We will be using Python for this tutorial. We will use requests module to talk to the websites.
- Selenium / Selenium wire: Selenium is the age old tool we all have been using to interact with a web app. It however, has many flaws, lack of speed being the primary one. We will use it in dire situations only. For example, we might use seleniumwire module to track network activities of a web app. Other than that we will stick mostly to requests.
Following are 10 things you need to know to build web scrapers
1. How to use Chrome Dev tools’ Elements tab
Let's say you want to scrape data from Wikipedia. First thing that you need to do is visit that Wikipedia link in Chrome and hit Ctrl+Shift+I. It will open your chrome developer tools.
Select the Elements tab in the dev tools. This is the html of your page. Now you decide what information do you want to extract from this webpage. Let’s say we want to extract this particular table from the page.
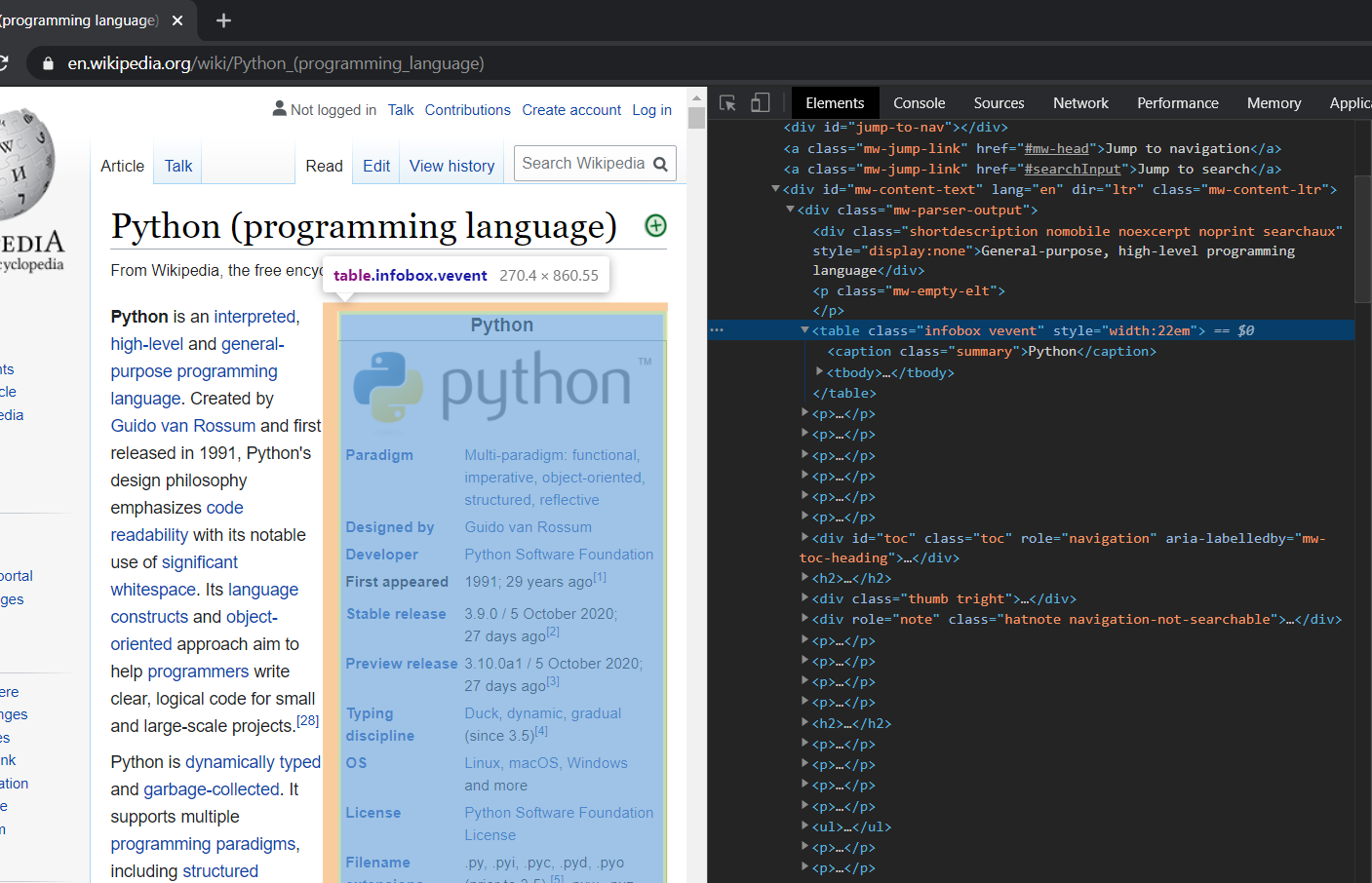
Now go to a part of the table and right click and then select Inspect. This will highlight that particular section of the webpage in the html code. Now in the Dev tools window hover your cursor in the parent of the element that you have clicked inspect on and it will highlight a section of page in the browser window. Keep looking for a html element until you find one that includes all of the sections that you want to get your data from. For this example it will be the div with class ‘infobox vevent’.
As we have figured out what we need from a page, we can get to scraping, which brings me to my 2nd point, that is:
2. Avoid requesting for the same page repeatedly while you’re writing the parsing logic
Request the URL, write the html in a file and try to parse the information out of the html file. When your parsing logic is solid, you can directly parse the response. Why it this helpful, you may ask. The reason to do this is so that you don’t get blocked by the site for too many request. Many sites will block you at a very small number of requests. While writing the logic you will have to try out different approaches to get the data, for which you need to do a lot of requests, which may get you banned.
import requests
resp = requests.get("https://en.wikipedia.org/wiki/Python_(programming_language)")
with open("wiki.html","w",encoding='utf-8') as f:
f.write(resp.text)
Once you have your page written to a file, comment out this part where you send the request and get to parsing.
For parsing we will be using BeautifulSoup. This is the most popular html parsers out there. The soup variable contains the parsed html, which we can query using the beautiful soup api.
Now we have found the table that we needed, we will go back to chrome to see which parts inside this table we want.
We want all the “tr” elements inside the table. Except the first one, we have a “th” and a “td” element in every “tr”. In this example we will not care about the links, we just want the texts. Will be storing this data in a dictionary data structure where keys will be text inside “th” tags and values will be text inside “tr” tags.
from bs4 import BeautifulSoup as BS
# soup contains the parsed html which you can query
soup = BS(open("wiki.html","r",encoding='utf-8').read(),"html.parser")
# find_all returns a list of results, find which one of the result is what you intended
# Here the first element is what we want is what we want
table = soup.find_all('table',"infobox vevent")
trs = table[0].find_all('tr')
data = dict()
for tr in trs:
th = tr.find('th')
td = tr.find('td')
#if we are able to find both td and th inside evry tr tag
if th and td:
data[th.get_text()] = td.get_text()
print(data)
Now in the “data” dictionary we have key-value pairs from the intended table. If that is all we wanted from this page our scraping operation has been completed. Now you can pass down this dictionary to be stored in file or to be written in a db for future use or pass it down to next processing element in your program that will use this data in some way.
( After you are satisfied with your results, remove the part where you are writing the response to a file and use resp.text instead of opening and reading that file)
3. How to use Chrome Developer tools' Network Tab
Believe me I after I got to know about this trying to write a scraper or a bot became much easier. The network tab will monitors every request a website is making to the backend servers. You will also be able to look at the structure of the request which is expected by the backend servers, which you will mimic in you code.
Before we talk about how to use the network tab, I will give a brief over view of the type of http requests we will be dealing with. (This is an abstract overview, which focuses only on the aspects that is necessary for web scraping)
A request to a webserver can be sent via two method: GET and POST. In both GET and POST request, you pass queries to a url. The key difference between these two, as far as we are concerned are:
- You can send a giant blob of data in a POST request, and GET has a limit on size of the data.
- When a site is sending async requests to the backend server it mostly uses a post request.
There are certain things that you send along with a GET or a POST requests. As many of the times you don’t want to look like a bot while requesting a sites resources, you’d have to mimic the structures of at least the following things:
- Headers: These are metadata of the requests. These are a set of key-value pairs sent to the server conveying some additional information based on which the server may treat your request differently. These are completely independent of the request body.Let’s say for some reason, you want to convey to the server that you’re sending the request from a mobile phone. How you can do that is by sending information about user-agent along with the request. In Python you do that as follows
header = {
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3559.0 Mobile Safari/537.36'
}
resp = requests.get("http://example.com/some-link",headers=header)
- Queries: You would want to specify what exactly you want from a server using queries. For example, let’s say you want to get the list of products from an e-commerce site where the product belongs to a certain category and the price is within range that you specify. In Python, you may send such a request like this.
# queries example
query = {
"category": "electronics",
"min-price": "100",
"max-price": "100000"
}
# It is a good practice to send headers with every request, unless you have a good reason not to do so
resp = requests.get(
"http://example.e-commerce-site.com",
headers=headers,
params=query
)
- Data: You may want to upload some data, an image for example, to a URL using a POST request. You can do that as follows:
# Upload example
img_path = '/path/to/some/image/file.jpg'
# This is a stream of bytes that we will send to the server
img_b = open(img_path,"rb").read()
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3559.0 Mobile Safari/537.36',
'content-lenght': len(img_b)
}
resp = requests.post(
"http://some-uload-api-endpoint.example.com",
data=img_b,
headers = headers
)
(Note: Pay attention to header we sent while uploading. We have sent an additional header ‘content-length’ which specifies the length of the stream of bytes that we are uploading.)
The site may have many such parameters passed with each request, figuring these out is crucially important, if we don’t want to threaten the webserver.
Chrome Developer Tools can help you figure these things out. Visit your desired site, hit CTRL + SHIFT + I, which will open your developer tools. Now click on the ‘Network’ tab.

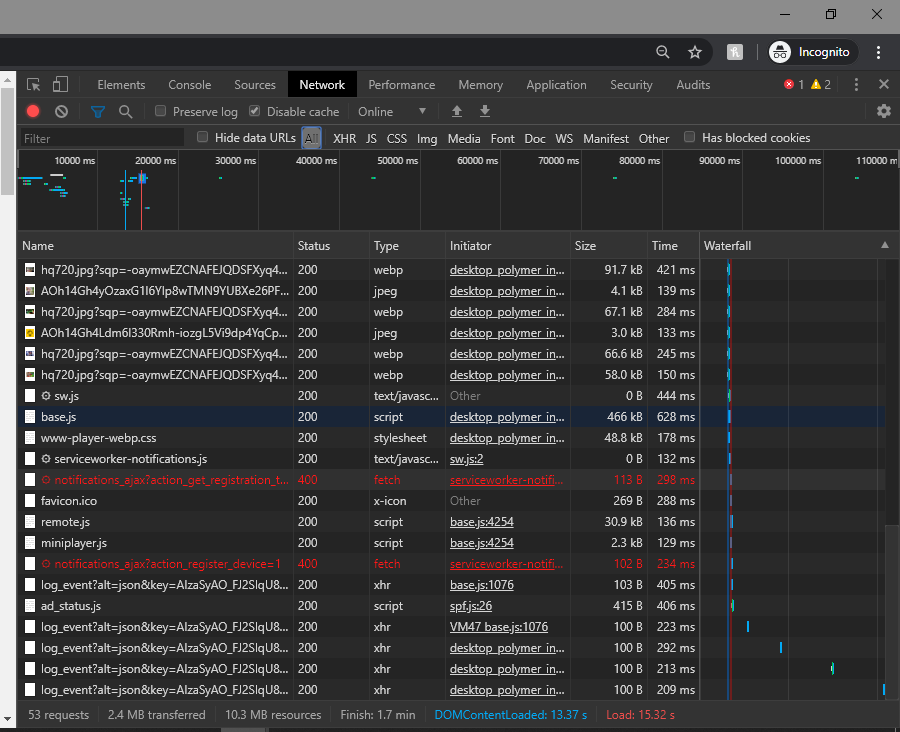
These are the list of all the all the request that site has been sending to the backend sever.
Let’s say you are interested in the response of one such particular request that you want to mimic using your Bot. What you can do is click on that particular request and you can see everything that has happened within that request: its headers, parameters, response. Everything.
Now let’s do a real example, shall we:
Reddit Bot
Let’s say, you want to see the top memes of today, (which you should do every day). So you visit r/memes and open developer tools and hit top today to see all the memes. Select the XHR filter in the network tab and you will find all the request reddit is sending back to the servers. Go to each of these and see which one is the request that was the result of you clicking “Top Today” option.

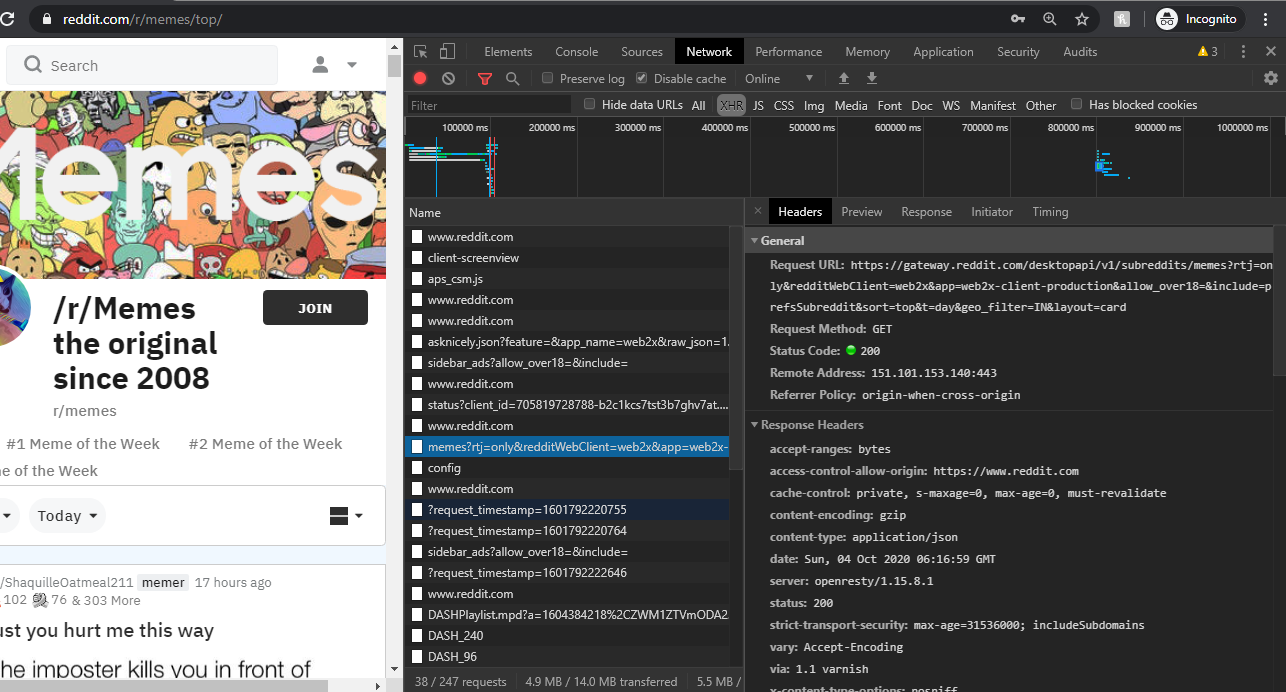
Click on that request and it will show you everything about that request. First pay attention to the request url
https://gateway.reddit.com/desktopapi/v1/subreddits/memes?rtj=only&redditWebClient=web2x&app=web2x-client-production&allow_over18=&include=prefsSubreddit&sort=top&t=day&geo_filter=IN&layout=card
What you see after ‘/memes?’ is the query that has been sent to the server. If you scroll down to the bottom of the screen you will see these queries in parsed form. Now if we discard the query parameters what remains is the API endpoint url, which in this case is:
https://gateway.reddit.com/desktopapi/v1/subreddits/memes
Now let’s look at the headers.

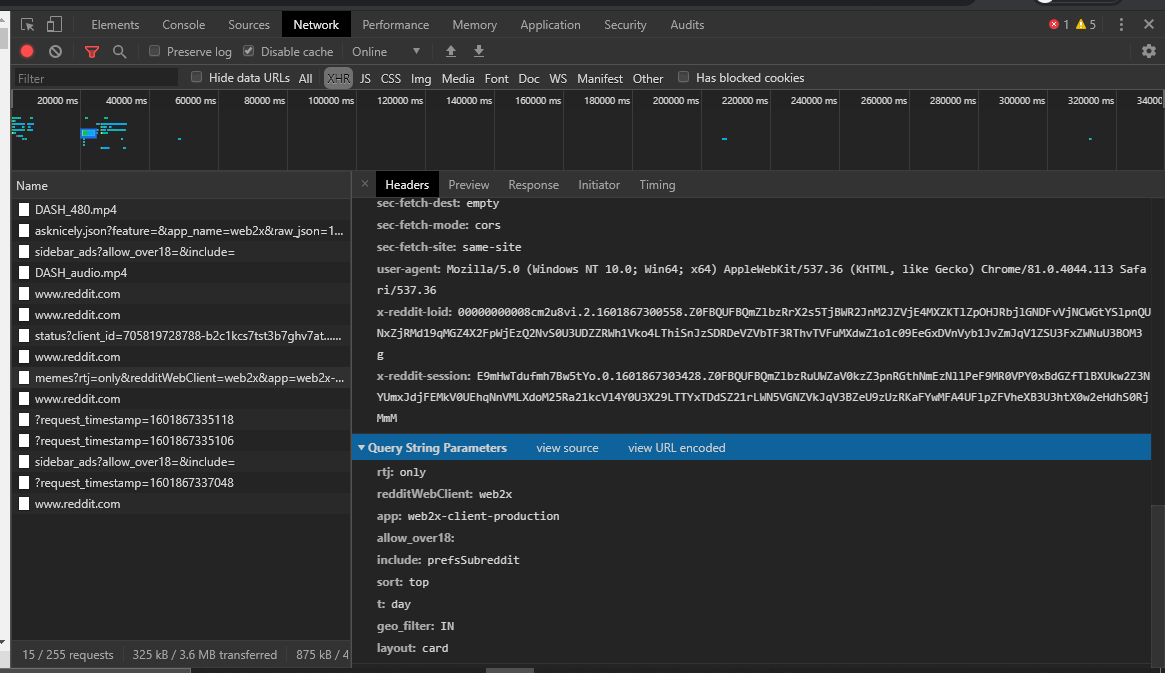
We will ignore the headers that start with colon as well as “x-reddit-loid” and “x-reddit-session” which are two session related headers. We will mimic the rest.
For the query we will use all the parameters except “include: prefsSubreddit”, as this one is asking for preferred subreddits, which we are not interested at the moment.
(Note: Reddit is forgiving in terms of what it expects in the headers. But if the site you’re trying to scrap expects everything intact you have to figure out how to get the values of each of these headers. )
Before sending the request, if you look at the “Response” tab, you will see we are receiving a JSON object as return. We can write that in a json file as we write our parsing logic, but here we will by pass that part and directly use the response. So out meme bot looks something like the following:
# redit example
import json
import requests
import re
# We will mimic the headers as is
reddit_headers = {
"accept": "*/*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-US,en;q=0.9,mt;q=0.8,bn;q=0.7",
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded",
"origin": "https://www.reddit.com",
"pragma": "no-cache",
"referer": "https://www.reddit.com/",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36"
}
reddit_query = {
"rtj": "only",
"redditWebClient": "web2x",
"app": "web2x-client-production",
"allow_over18": "",
"sort": "top",
"t": "day",
"geo_filter": "IN",
"layout": "card"
}
url = "https://gateway.reddit.com/desktopapi/v1/subreddits/memes"
resp = requests.get(url,headers=reddit_headers,params=reddit_query)
_json = json.loads(resp.text)
# You can remove this part once you are sure with the parsing logic
with open("reddit.json","w") as f:
json.dump(_json,f,indent=2)
# We need to make sure that we are downloading memes, not the ads
# So we will validate the url to see if it is a reddit url or not
# For that we will use the following regex to match with "permalink"
is_post_rx=re.compile(r'https://www\.reddit\.com/r/')
for id, info in _json["posts"].items():
# We only care about the images that are not ads
if info["media"]["type"] == 'image' and re.match(is_post_rx,info["permalink"]):
print(f"Dowloading {id}.jpg")
# Now we will request for the memes and write them in a file as jpg images
# Make sure "memes" directory is created
with open(f"./memes/{id}.jpg","wb") as img:
resp = requests.get(info["media"]["content"],headers=reddit_headers)
img.write(resp.content)
The take away of this example is as follows:
a) Use Chrome developer tools network tabs to find out what is the expected structure of requests
b) Do the process step by step figuring each piece out, and then combine all of the pieces to create a unified flow.
c) It brings me back to my next point which is:
4. Err on the side of calling an backend API over parsing HTML pages
What we have done with r/memes could probably have been done by requesting https://www.reddit.com/r/memes/top/ and parsing the HTML page. And what we have done is, we requested a backend API to get the data readily. So it is almost always easier to request such API endpoint, because parsing HTML can be pain if your site loads content dynamically.
This is not to say that don’t do HTML parsing at all, but do it sparingly.
5. Don’t overwhelm the API / webserver
It may seem inconspicuous and innocent action to send a million request to a webserver just because you can. But the webserver may have implemented some measures to prevent DoS or DDoS attacks. So, by looking at with a high rate of requests the webserver can be fairly certain that you are not a regular user, you in fact are a bot. And they will blacklist your IP or worse ban your user if you happened to be logged in. So don’t do that. Place some random interval between every request, so that you can seem like a human browsing the internet.
6. Request limitation? Use proxy and user agents
In the previous point I said not to overwhelm the API. But if you have to do it these are the ways to get away with it
- Use sessions to hold cookies. ( Discussed in the next point )
- Google for user agents. Store them In a list. Update the header with a new user-agent every request.
- Use proxy. Google for free proxy, store them in a list. Use a different proxy for every request.
The order of this list is important. Using sessions and rotating through user agents will get you through small scrape work. You cannot use sessions if you are sending a tons of request, because they can just ban the user. If the job is of significant scales you’d have to use proxies.
How to use free proxies ( or any unreliable proxy services)
Many of the free proxies you find on the internet does not work or are dreadfully slow. So following is a very clean strategy to use them, without your scrapper failing in between due to connection error.
import random
import requests
from tenacity import stop_after_attempt, retry
class ProxyRequest:
def __init__(self):
# You can also use paid proxy services here. The way to use them will be quite similar
# These are all free https proxies I got from https://free-proxy-list.net/
self.proxies = [
"91.202.240.208:51678",
"2.187.212.182:8080",
"196.2.14.250:45521",
"103.102.14.128:8080",
"124.41.211.211:43979",
"51.75.147.44:3128",
"103.242.106.32:80",
"102.130.128.13:3128",
"51.15.150.114:3838",
"91.121.110.174:3128",
"1.20.100.45:51685",
"212.83.174.222:3838",
"144.217.101.245:3129"
]
self.user_agents = [
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1",
"Mozilla/5.0 (Windows NT 6.3; rv:36.0) Gecko/20100101 Firefox/36.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10; rv:33.0) Gecko/20100101 Firefox/33.0",
"Mozilla/5.0 (X11; Linux i586; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20130401 Firefox/31.0",
"Mozilla/5.0 (Windows NT 5.1; rv:31.0) Gecko/20100101 Firefox/31.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:29.0) Gecko/20120101 Firefox/29.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/29.0",
"Mozilla/5.0 (X11; OpenBSD amd64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (X11; Linux x86_64; rv:28.0) Gecko/20100101 Firefox/28.0",
"Mozilla/5.0 (Windows NT 6.1; rv:27.3) Gecko/20130101 Firefox/27.3",
"Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:27.0) Gecko/20121011 Firefox/27.0",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:25.0) Gecko/20100101 Firefox/25.0",
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Windows NT 6.0; WOW64; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:24.0) Gecko/20100101 Firefox/24.0",
"Mozilla/5.0 (Windows NT 6.2; rv:22.0) Gecko/20130405 Firefox/23.0"
]
# After these many seconds, it will give up trying to use one proxy
self.timeout = 5
def get_random_proxy(self):
rand_proxy = random.choice(self.proxies)
return {
"http" : f"http://{rand_proxy}",
"https" : f"https://{rand_proxy}"
}
# This retry decorator will call proxy get multiple times
# If the the random proxy that it have selected does not respond
# It will raise an exception only when, if have tried 10 times with diffrent proxies and
# None of them responded
@retry(stop=stop_after_attempt(10),reraise=True)
def proxy_get(self,*args,**kwargs):
kwargs['proxies'] = self.get_random_proxy()
kwargs['timeout'] = self.timeout
if headers in kwargs:
kwargs['headers'].update( {'user-agent' : random.choice(self.user_agents)} )
else:
kwargs['headers'] = {'user-agent' : random.choice(self.user_agents)}
# It will raise exeption if status is not 200
with requests.get(*args, **kwargs) as resp:
r.raise_for_status()
return r
if __name__=="__main__":
proxy = ProxyRequest()
# We will pretend we have some links in this list
links = list()
for i in links:
resp = proxy.proxy_get(i)
# Do something with the response
7. Login and Sessions: What if the data that you want is behind a login screen?
In that case we need to login. Though logging into a site is almost always same there can be slight differences in terms of what you send as the parameters and headers. For this example, we will again use Reddit.
Let’s try to find the request from the browser that sends your credentials back to the server. (Use a wrong password, so that you don’t get sent to the homepage after login).
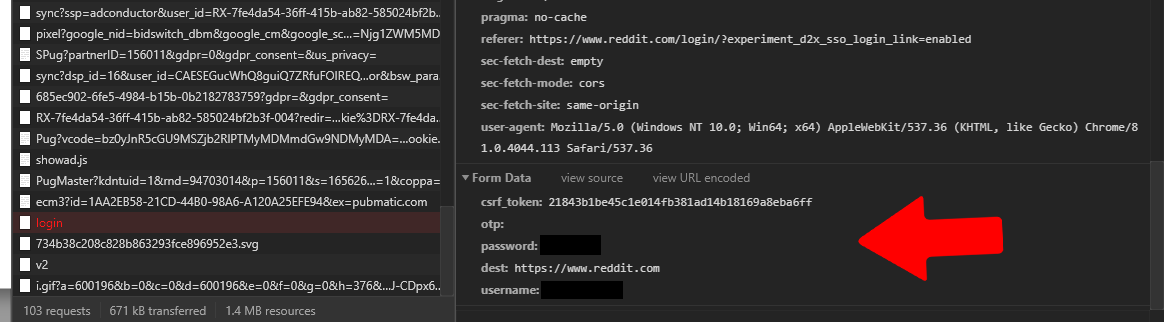

Pay attention to the form data. Along with username and password it is sending “otp”,”destination”, and “csrf_tokken”. These are the things that will differ from site to site.
Now the question is how do you figure out the value of “csrf_tokken”? If you search for the value of the csrf_tokken sent with our initial login request, you will find out that when you click on the login button on reddit, you recieve a form, and in the body of it contains the csrf_tokken we are looking for.
Nice. Now we will make a request for this page, parse out the csrf_token, and then we will send a request to the login url wit the things it needs. To extract the csrf_token we can parse the html, but my preferred way is to use Regex, which brings me to my next point:
8. Use regex instead of parsing HTML
Parsing the entire html for one single bit of information does not makes sense, at least to me. So we will use a simple regex to get the csrf_token for the login. To make sure our regex works, go to the “Response” tab of the request in Chrome dev tools and copy the html into a python shell and try to write your regex. Once you succeed, Use that regex to in your code.
So the following is the code to login to Reddit:
import requests
import re
# As before we are mimicing the browser headers
chrome_header = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-US,en;q=0.9,mt;q=0.8,bn;q=0.7",
"cache-control": "no-cache",
"pragma": "no-cache",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36",
}
# A Session manages cookies of a login session for us
session = requests.Session()
resp = session.get(
'https://www.reddit.com/login',
params={'experiment_d2x_sso_login_link': 'enabled'},
headers=chrome_header
)
csrf_token = re.search(r'<input\s+type="hidden"\s+name="csrf_token"\s+value="(.*?)">', resp.text).group(1)
# If you have two factor authentication enabled take otp as input
username = input("Username: ").strip()
password = input("Password: ").strip()
resp = session.post(
"https://www.reddit.com/login",
headers = chrome_header,
data = {
"csrf_token": csrf_token,
"otp": "",
"password": password,
"dest": "https://www.reddit.com",
"username": username
}
)
# This will throw an error, if login goes not return status 200
resp.raise_for_status()
print("Login succesfull.")
# Now you can use the session object to request URLs that requeirs login as follows
resp = session.get("http://reddit.com/some-link-to-nsfw-content")
# Enjoy!
9. Parallel processing: If you need to collect and process huge amounts of data
If we need to collect huge amounts of data, there are multiple problems we need to deal with:
a) Does your target site allows it? A site can ban you after only a hundred quick requests. It will figure out that no human can send requests that fast and you must be a bot and hence will blacklist your IP address. You can get around this problem by using proxies and changing user agent every now and then.
b) What if the data that you want is behind a login screen? Then you are at the mercy of the site. Because if you login they can see from who the request is coming and can ban that particular user. Put sleeps in between requests to make it seem like a real human. If you somehow cannot create a huge number of fake accounts, your dream of collecting huge amount of data is gone.
We will try to send huge amount of request to an imaginary site. This method will borrow the ProxyGet class that we wrote earlier and we will use Thread pool executors to send parallel requests.
if __name__=="__main__":
proxy = ProxyRequest()
# We will pretend we have a huge amount of links in this list
huge_amount_of_links = list()
# We will use 20 threads to send parallel requests
executor = ThreadPoolExecutor(20)
futures = { executor.submit(proxy.proxy_get(link)) : link for link in huge_amount_of_links }
for f in as_completed(futures):
resp = f.result()
# TODO: process the response here
You may have paid attention to the code and noticed that we are sending the requests in parallel and then processing the results in the one single thread. It’s not parallel processing after all, is it?
Yes, you are right. It is not parallel processing. See, how threads are implemented in python is that they are just time shared multiplexing of one single thread. We are not processing responses in parallel, but since an http network call takes a long time compared to time frames of a CPU, if we wait for each request to return a response to send the next request we are wasting a lot of time. That is the amount of time we are saving here. What is happening here is, we sent out requests without waiting for them to return. When one request returns it is processed immediately.
I hope this makes sense. If you want to do parallel processing in python look into multiprossesing. This may be a good place to start: Python multiprocessing.
10. Desktop site too hard? Try the mobile version of the same site
Many of the times there are a lot of restriction on the desktop version of the site but not on the mobile version of the same site (which is not necessarily true for all the sites). But I have tried this a couple of times it worked. So it’s worth sharing.
The theory I have on why this works is that websites that have a desktop version, a mobile version and an mobile app uses the same API for both the app and the mobile sites hence they put less security on these as these are less exposed to people like us trying to access the huge amounts of data. IDK, it just a theory.
You can request the site through Chome developer tool as a mobile device, to inspect the network tab. To do that hit CTRL+SHIFT+I and click on toggle device option as shown below.


Anyway, using python, how you get to the mobile site is by sending a header with a mobile user agent
# mobile user agent
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3559.0 Mobile Safari/537.36'
}
resp = requests.get("http://some-link.example.com",headers = headers)
Interacting with a web app: Advanced Bots
The traditional way of programmatically interacting with a web app has always been selenium browser automation. Which is a really easy but messy way to do it because of one primary reason: The GUI is the part of an app that is most frequently changed. So if you’re writing a bot on top of a GUI your code will break on the slightest change in how user is expected to interact with the app. So the other better way to interact with a web app is through its API, which is less likely to change as compared to the GUI.
Alright, How do you do this? Chrome developer tools is the savior here, again.
See, every action on the web app sends one or more asynchronous request to the server, each of which contains information about the action that you have performed. So if you understand how the browser is talking to the server you can eliminate the browser entirely from the picture and do the talking directly through http requests. This way of doing is preferred because of two reasons: a) It is easier to maintain state, as you will not have to deal with those pesky popups. b) You don’t have to wait and check for browser to complete rendering the webpage before you can press a button or get some data.
So next time when you are building a bot, instead of jumping to selenium, wait and take a look at the network tab of chrome. You might easily be able to figure out the API and your code will be much easier to maintain.
Anyways, I hope this will be of some help when you are doing you next web scraping project.
Thanks for reading.